
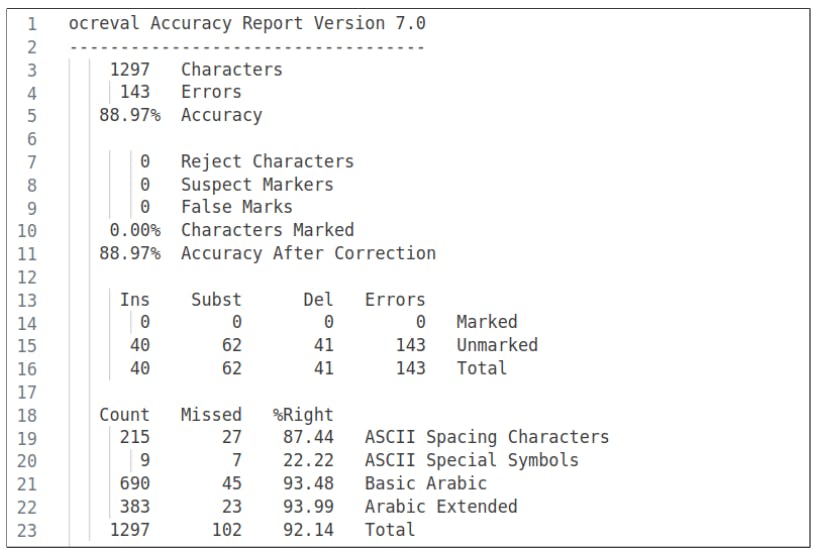
Key Challenges in OCR Research and Future Directions
20 Aug 2025
Discover the key challenges of OCR research, from spacing errors to math equations, and what’s next for improving text recognition.
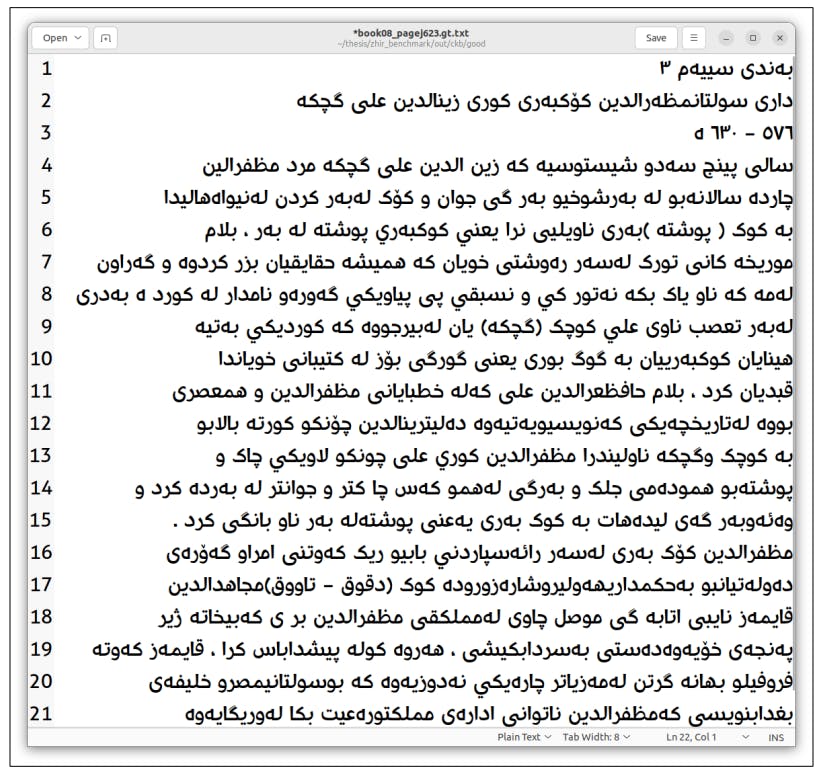
Training Tesseract for Low-Resource Languages
20 Aug 2025
Unlocking Kurdish history with OCR: How Tesseract was trained to digitize rare documents and preserve a low-resource language.
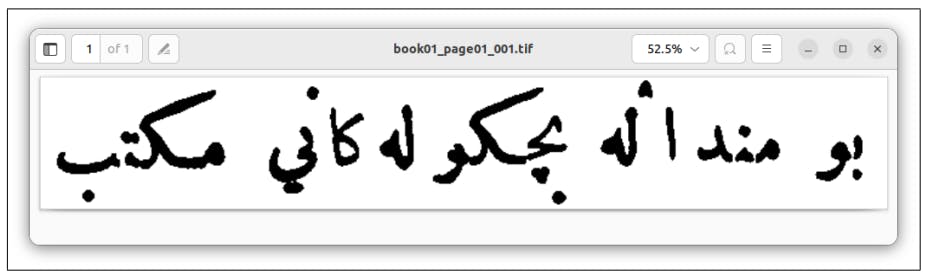
Why OCR Struggles With Multi-Column Pages
20 Aug 2025
Retraining OCR with Kurdish data: results, challenges, and how this model could unlock libraries and archives for low-resource languages.

Training Tesseract OCR on Kurdish Historical Documents
19 Aug 2025
Digitizing fragile Kurdish archives with Tesseract OCR: dataset creation, image processing, and training experiments explained.

Why Your Tesseract OCR Results Suck (and How to Fix Them Fast)
19 Aug 2025
Digitizing history with Tesseract OCR: from preprocessing to evaluation, learn how to boost accuracy when training on old documents.

Building OCR Systems for Tamizhi and Kurdish Historical Documents
19 Aug 2025
Digitizing Tamizhi and Kurdish historical texts with OCR is tough. Here’s how AI models like LSTM and CNN are making breakthroughs.

Improving OCR Accuracy in Historical Archives with Deep Learning
18 Aug 2025
AI-driven OCR methods like LSTM and CNN-LSTM are revolutionizing historical document digitization, boosting accuracy up to 98%.

Advances in OCR for Historical Chinese, Japanese, Coptic, and Greek Texts
18 Aug 2025
AI breakthroughs in OCR are decoding historical Chinese, Japanese, Coptic, and Greek texts with accuracy gains up to 94%.

Can AI Finally Crack Ottoman Text Recognition?
18 Aug 2025
Discover why OCR systems still struggle with Arabic, Persian, and Ottoman texts, and how AI and deep learning are shaping breakthroughs.