
Table of Links
1.1 Printing Press in Iraq and Iraqi Kurdistan
1.2 Challenges in Historical Documents
-
Related work and 2.1 Arabic/Persian
-
Method and 3.1 Data Collection
3.2 Data Preparation and 3.3 Preprocessing
3.4 Environment Setup, 3.5 Dataset Preparation, and 3.6 Evaluation
-
Experiments, Results, and Discussion and 4.1 Processed Data
4.4 Results and Evaluation
After completing the training, we evaluated the model using different methods. In this section, we show the results for each evaluation method. During the training process, the trainer produces a report that outlines the model’s accuracy every 100 iterations. Once the training was completed, we assessed the model using Tesseract evaluation and obtained a minimal training error rate (BCER) value of 0.755%.
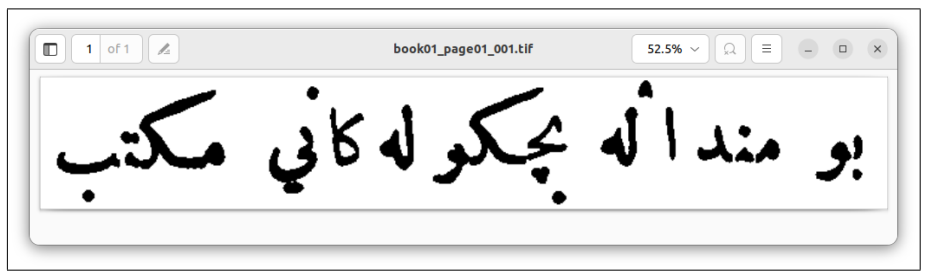
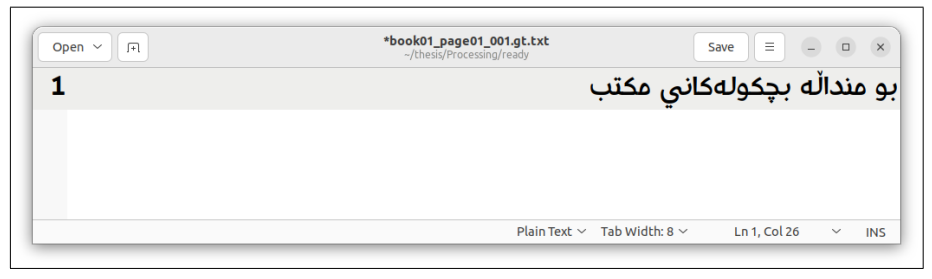
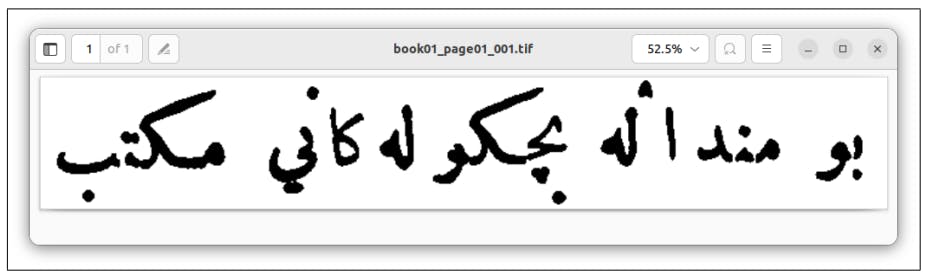
We randomly chose a subset of pages from the collected data which were not utilized in the model’s training and testing. These pages were manually transcribed, and the page images and their corresponding manual transcriptions were submitted to Ocreval for evaluation. The outcomes of this evaluation can be observed in Figures 18, 19, 20, and 21.
4.5 Discussion
The limited availability of resources presented significant challenges during our data collection process. Converting the collected data into a digital format proved to be an additional obstacle, for which we received support from the Zheen Center for Documentation and Re- search. Manual transcription of the documents posed considerable difficulty due to unclear text, non-standard spacing between words and characters, and unique vocabulary influenced by Arabic letters and terminologies. Also, we discovered that the system has challenges in properly extracting text from multi-column pages and mathematical equations.
We retrained an existing Arabic model using our unique Kurdish dataset in this research, which yielded remarkable outcomes. Considering our findings, if we further train the model on a larger dataset, it has the potential to produce results suitable for production use. Such a model can significantly aid libraries and centers in effectively extracting text from historical documents.
Authors:
(1) Blnd Yaseen, University of Kurdistan Howler, Kurdistan Region - Iraq ([email protected]);
(2) Hossein Hassani University of Kurdistan Howler Kurdistan Region - Iraq ([email protected]).
This paper is