
Table of Links
-
Related Work
2.1 Semantic Typographic Logo Design
-
3.1 General Workflow and Challenges
-
Discussion
8.1 Personalized Design: Intent-aware Collaboration with AI
8.2 Incorporating Design Knowledge into Creativity Support Tools
7 EVALUATION
To test the effectiveness of TypeDance, we conducted a baseline comparison and user study. Our primary objective was to evaluate the performance of generated results and the usability of TypeDance, and explore how each component could potentially address pain points in their design workflows. Additionally, we delved into the limitations of the tool and identified opportunities for improvement.
7.1 Baseline Comparison
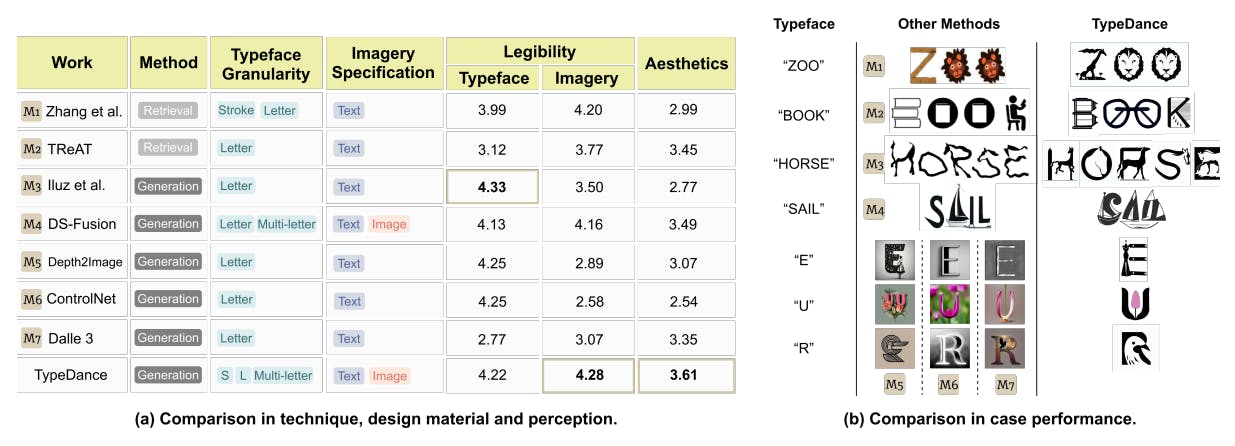
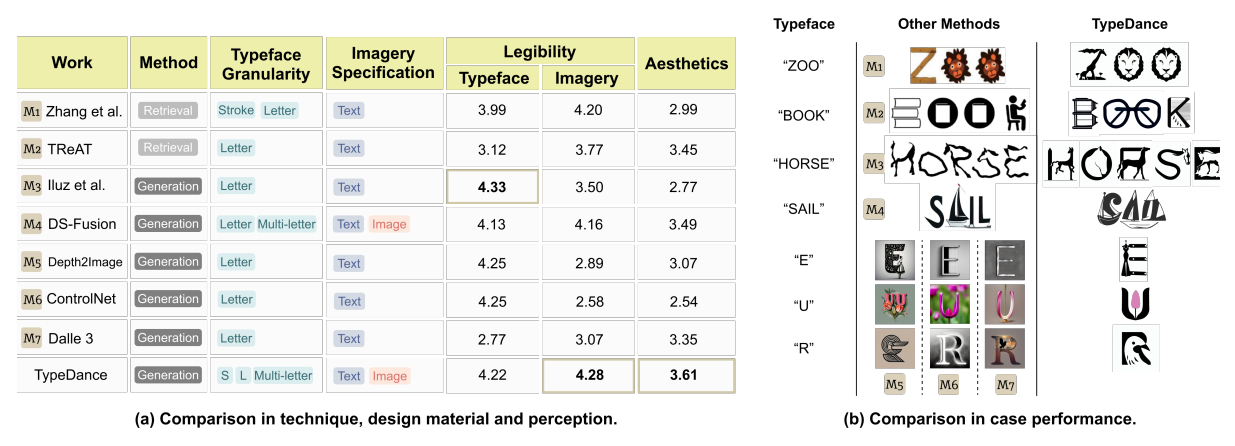
We conducted a comparison with seven alternative methods: Zhang et al. (M1)[61], TReAT (M2)[48], Word as Image (M3)[23], DS-Fusion (M4)[47], Depth2Image (M5)[34], ControlNet (M6)[63], Dalle 3 (M7)[5]. For a comprehensive evaluation, we assessed these methods from both technical and perceptual perspectives, as depicted in Fig 6. Given that most works are not open-source, an overall comparison using the same case was not feasible. Instead, we randomly sampled three cases from each method and utilized TypeDance to recreate them with the same text content and imagery, taking a one-to-one comparison with each method. The full cases are listed in the supplemental material. The perception study involved an online questionnaire with the participation of 50 individuals. We shuffled the appearance sequence of
all logos and provided no hints about the original typeface or imagery used, and the scores were recorded on a 5-point Likert scale.
7.1.1 Technique Difference. Artistic typography and TReAT operate on a retrieval-based approach, which limits their ability to generalize to cases significantly different from the collected templates. In contrast, other methods adopt a generation-based approach, offering some alleviation to this limitation. However, most of them are restricted to letter-level blending, whereas TypeDance excels by supporting blending at all typeface granularity. Regarding the interaction to specify imagery, the majority of methods rely on text, either by retrieving relevant templates from a corpus or guiding the generative model. Notably, DS-Fusion and TypeDance stand out as they support using images to assign specific visual representations. It’s worth noting, though, that DS-Fusion necessitates users to provide a small image dataset of around 20 images for fine-tuning the model, a process taking approximately 1.5 hours using a desktop with Nvidia GeForce RTX 3090.
7.1.2 Perception Study. We used two primary metrics to assess the performance of these methods: one focused on the legibility of typeface and imagery, and the other on aesthetics. As illustrated in Fig. 6, TypeDance outperforms other methods in both aesthetics score and legibility of imagery. Word as Image achieves the highest score in the legibility of typeface, but its imagery is comparatively challenging to recognize. Similarly, many methods exhibit this imbalance, excelling in one representation while compromising the other. In contrast, TypeDance maintains a stable performance with commendable aesthetic recognition.
7.2 User Study
7.2.1 Participants. Both designers and general users (11 females and 7 males, aged 19-34) are invited to obtain different feedback. Nine participants (P1-P9) are novice users interested in semantic typography art without formal design training. The remaining nine are graphic designers (E1-E9) with professional design education with more than three years of experience in semantic typographic logos. All participants have tried AI tools like Midjourney before. They accessed TypeDance through web browsers, utilizing a combination of online and offline modes. As a token of appreciation, each participant received a $30 gift card upon completing the study.
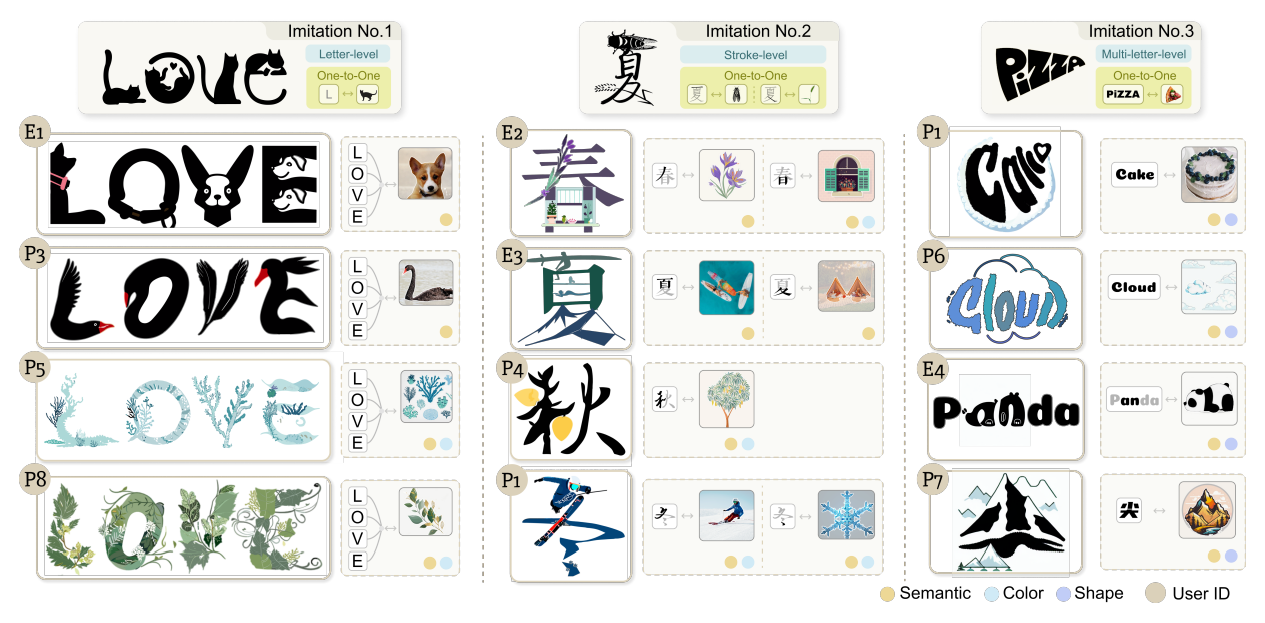
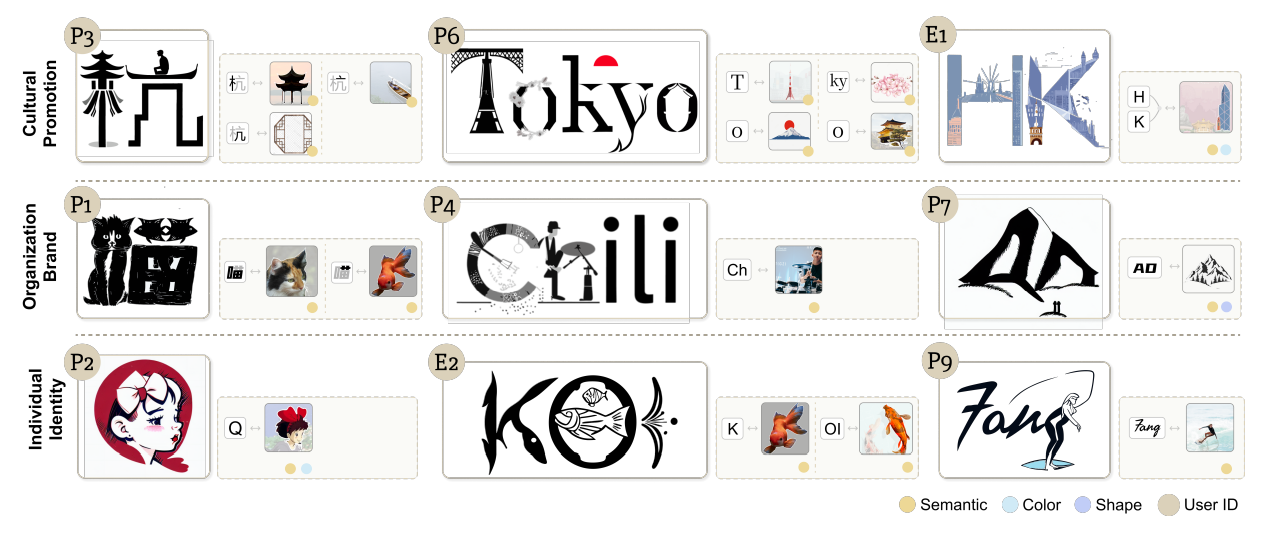
7.2.2 Tasks and Procedure. Drawing inspiration from the design process outlined by Okada et al. [35], which contains two essential stages, namely imitation and creation, we crafted two tasks accordingly to align the natural and progressive design challenges. The comprehensive procedure is outlined as follows:

Authors:
(1) SHISHI XIAO, The Hong Kong University of Science and Technology (Guangzhou), China;
(2) LIANGWEI WANG, The Hong Kong University of Science and Technology (Guangzhou), China;
(3) XIAOJUAN MA, The Hong Kong University of Science and Technology, China;
(4) WEI ZENG, The Hong Kong University of Science and Technology (Guangzhou), China.
This paper is